Fine-tuning Large Language Models explained in 10min

Video
Introduction
This post serves as a note-taking guide and a knowledge graph for the video.
Fine Tuning
Fine-tuning is the process of taking a pre-trained model and customizing it for a specific task or dataset. Pre-trained models are the new hires . To make them effective for your specific tasks, you need to train them further using a custom dataset. This process is called fine-tuning.
Company or Research Institutions may have their private document repository. In order to let AI work in these organizations, they may need to let AI read through the documents. This is the process that let AI model to learn from these private documents.
Why Fine Tuning is Important
Fine-tuning is an excellent starting point for developing AI-based applications. Because it has many benefits.
Cost Efficiency
Reduced Training Time:
Adaptability (or Task Specialization)
Model Evaluation
We need to define metrics to evaluate performance. It depends on the task . For classification, we can use accuracy, and for regression, we can use MSE, etc.
Most of AI models today are using large-Largement models, which is used for text generation tasks.. To evaluate their performance, we typically use metrics like BLEU and ROUGE. In order to get familiar with these two, we need to understand three things: precision, recall, and n-grams.

Precision is all about accuracy. It tells us how many of the results the model gave us were actually correct. If the model provides 5 words and 3 of them are correct, the precision will be 3 over 5.
Recall is a bit different. It looks at how many of the correct answers the model was able to find out. If there are 6 words consider correct and model provides 3 of them. The recall would be 3/6.
N-grams are just sequences of words. For example, a bigram is two words together, like “the cat”.
With above concepts, we can discuss BLEU and ROUGE:
BLEU
BLEU (Bilingual Evaluation Understudy) is all about n-grams precision. It checks how many n-grams in the model’s output are in the n-grams of reference text. The higher BLEU score, the more n-grams matched.

There is a loophole of precision. That is the model only needs to provide two word sentences and both words are correct. Then the precision will be 1. In order to avoid that. BLEU introduced Brevity Penalty (BP), which prevents the model from cheating by generating overly short answers.

ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation), focuses more on recall. It looks at how many important n-grams from the reference text are captured by the model’s output.
ROUGE is a family of metrics, like ROUGE-1, ROUGE-2, etc. The number indicates which n-gram it focuses on.

Fine-Tuning Techniques.
There are many ways to perform fine-tuning. I divide them into three categories, prompt engineering, regular fine-tuning and reinforcement learning.
Prompt Engineering
In this method, we don’t modify any parameters in the model. Instead, we manipulate the prompt to trigger the pre-trained model’s capabilities for specific tasks. It's more like the model knows how to do the task. We need some special word to guide the model to do the task.
Regular Fine-Tuning
There are two direction of regular Fine-Tuning: Full Fine-tuning and Parameter Efficient Fine-Tuning or PEFT.
Full Fine-Tuning
Full fine-tuning means adjusting all the parameters in the model, essentially continuing its training process. The key component here is the dataset.
Single Task Dataset: We can fine-tuning the model on a single-task dataset. But it might cause catastrophic forgetting
catastrophic forgetting: the model becomes highly specialized in one task but loses its ability to handle others
Multi Task Dataset: It’s recommended to multi task fine-tuning. Using multi task dataset to preserve the generalization ability.
Parameter Efficient Fine-Tuning(PEFT)
These methods adjust fewer parameters while achieving similar effectiveness. There are three main directions of PEFT:
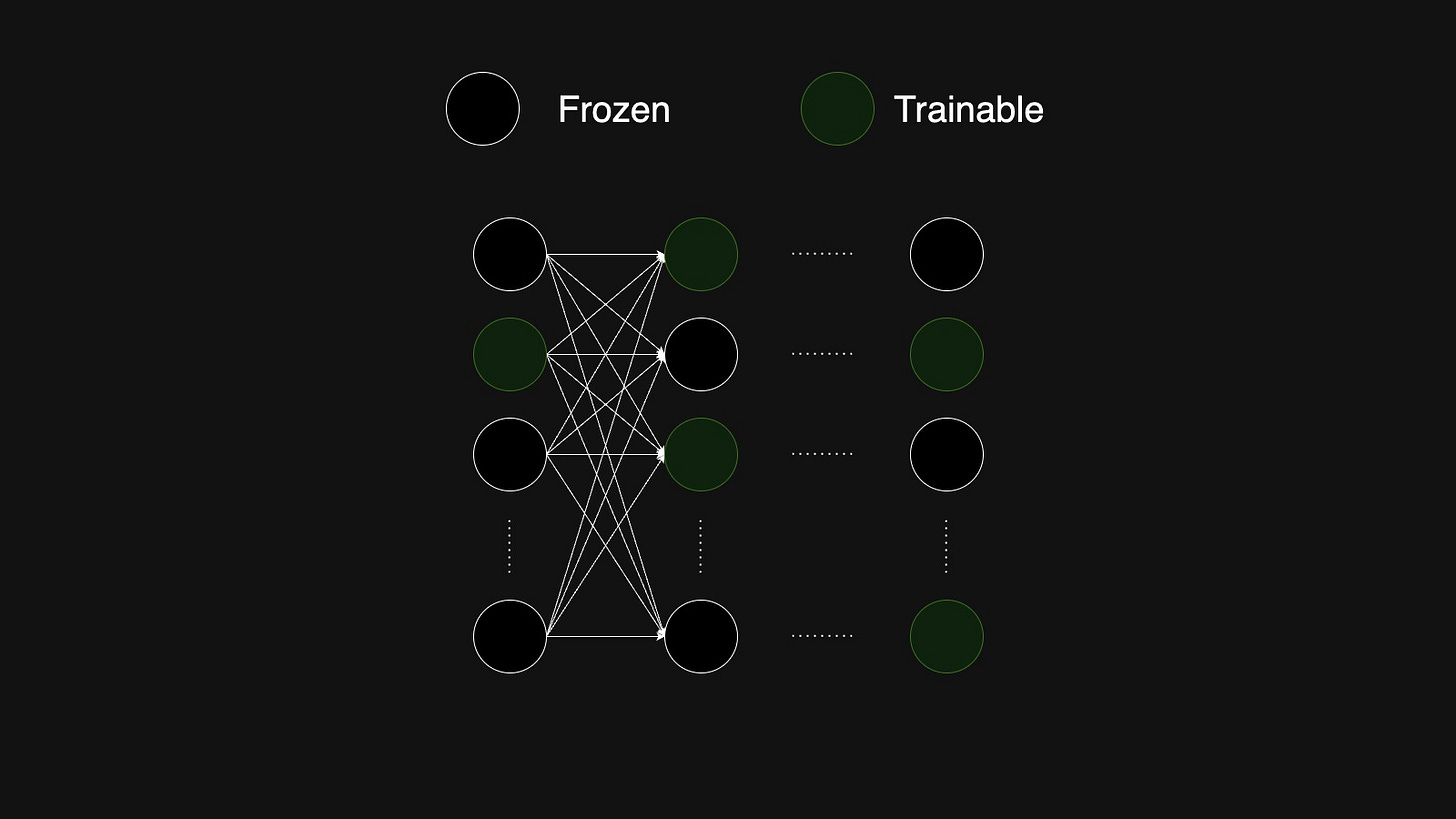
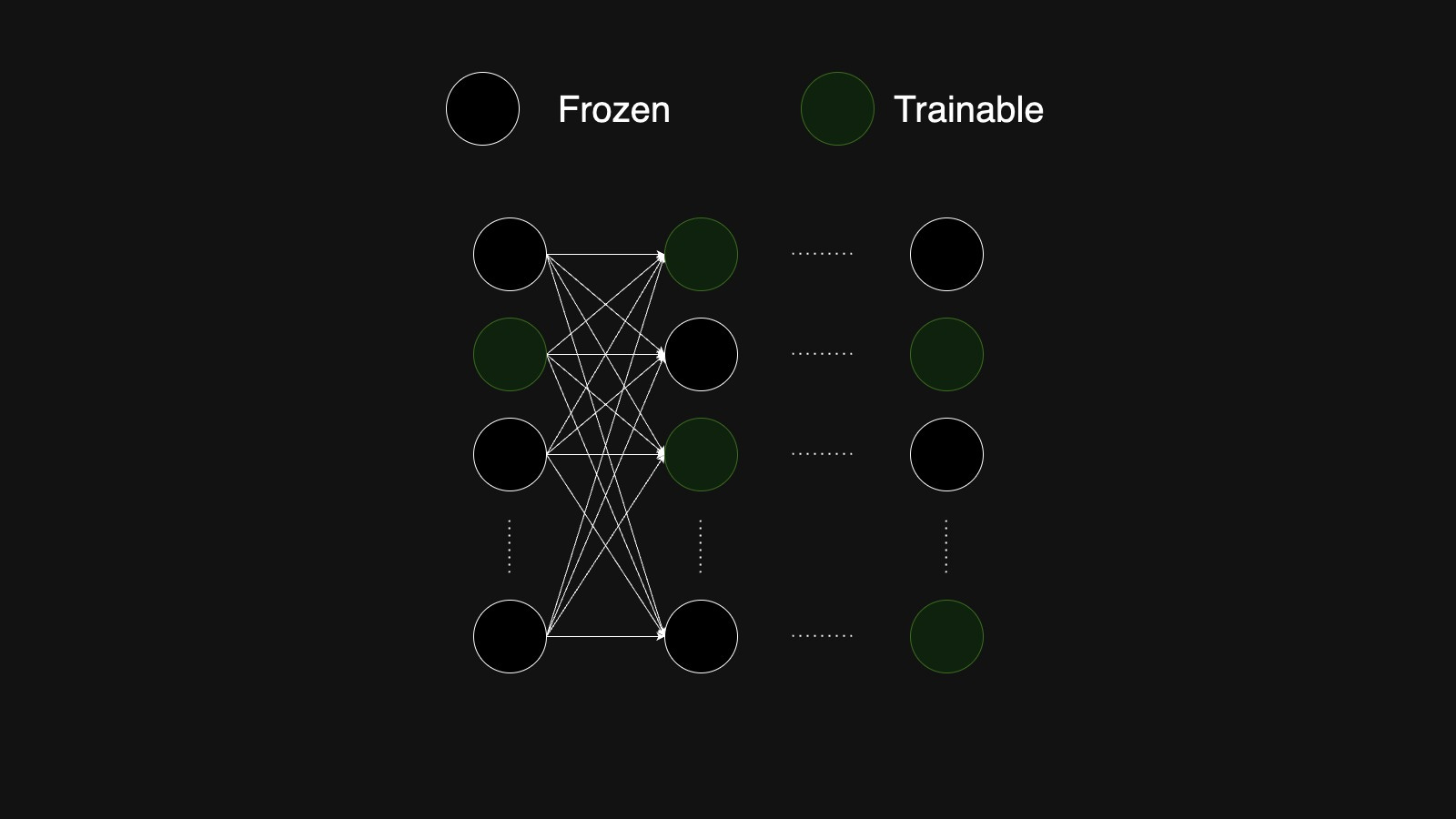
Selective Fine-Tuning: In this method, we freeze most of the model’s parameters and only trains a few.
Selective fine-tuning Reparameterization: Reparameterization in fine-tuning refers to transforming the parameter space of a model to enable more efficient training. One popular method is LoRA(Low-Rank Adaptation)
In neural network, parameters are represented as a matrices (W).
The training process is practically finding the changing matrices (Delta W) that will be added into the parameter matrices.
LoRA breaks down the change matrices into smaller, low-rank matrices (delta W = AB). Then we only need to calculate these low rank matrices.
The trainable parameters will be much smaller than the original change matrices.

LoRA example
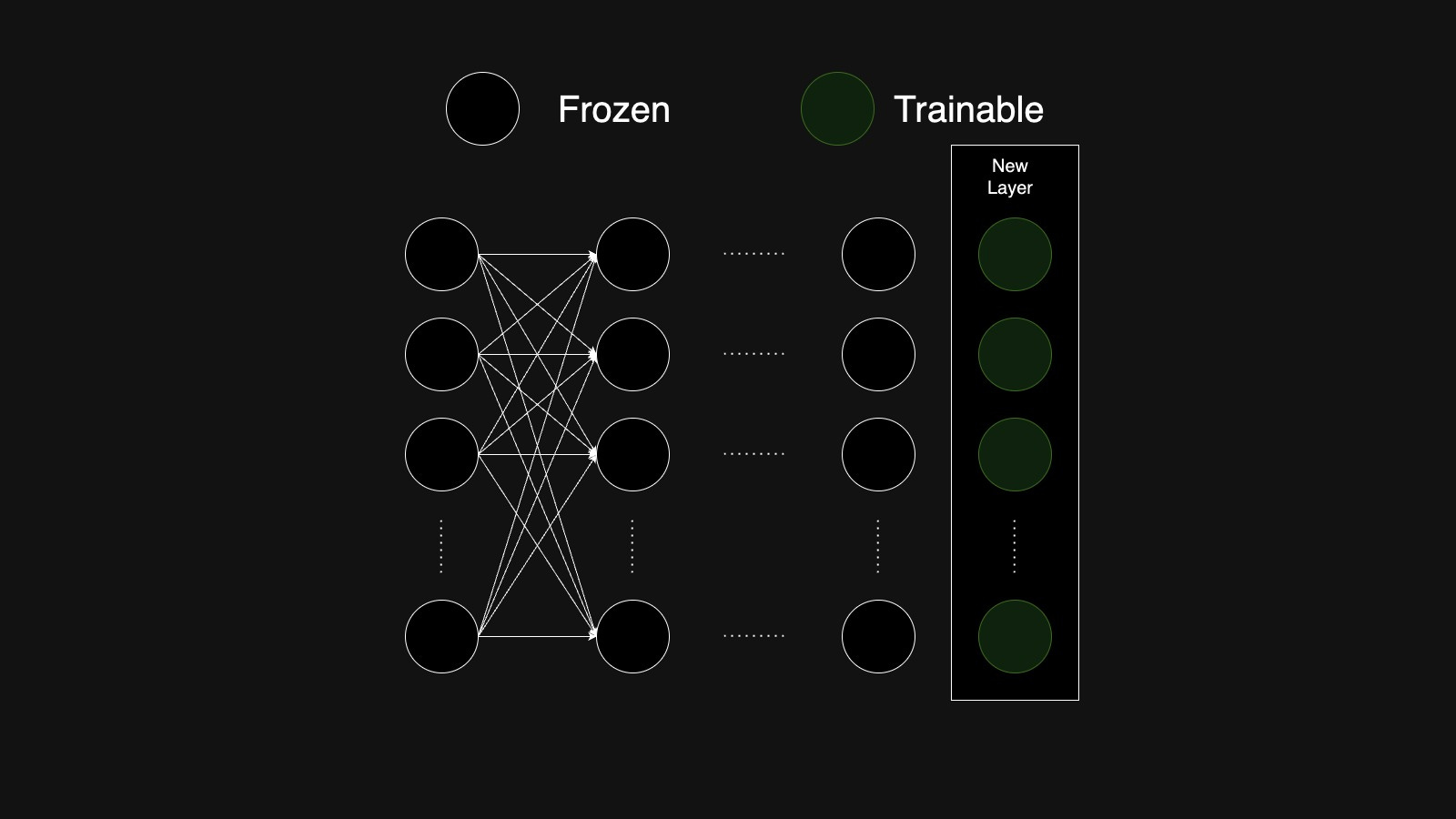
Additive Fine-Tuning: This method adds new, trainable components. We can either add trainable layers to the model or we can add trainable prefix token or embedding to the input sequence.
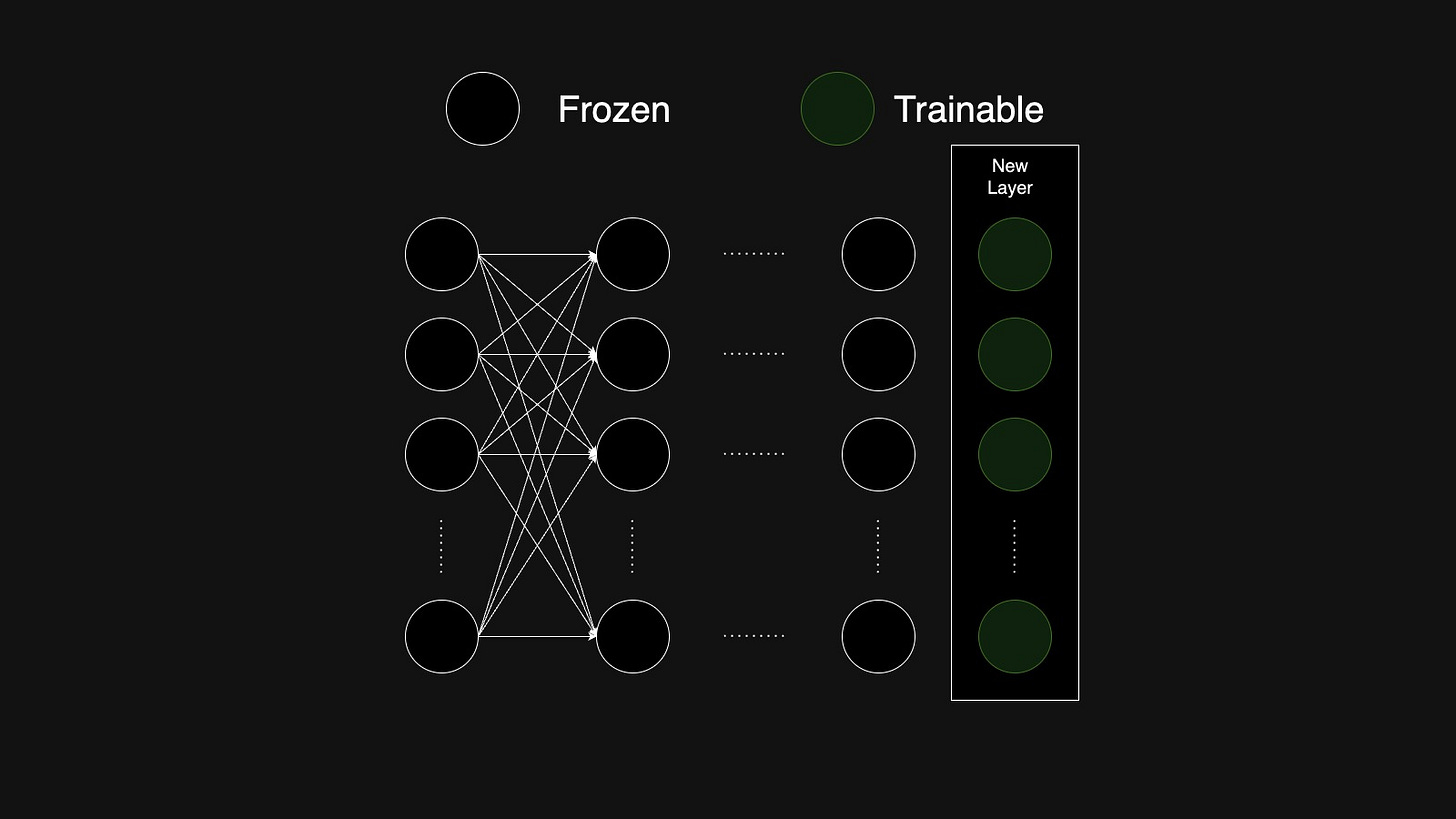
Adding new layers to the model 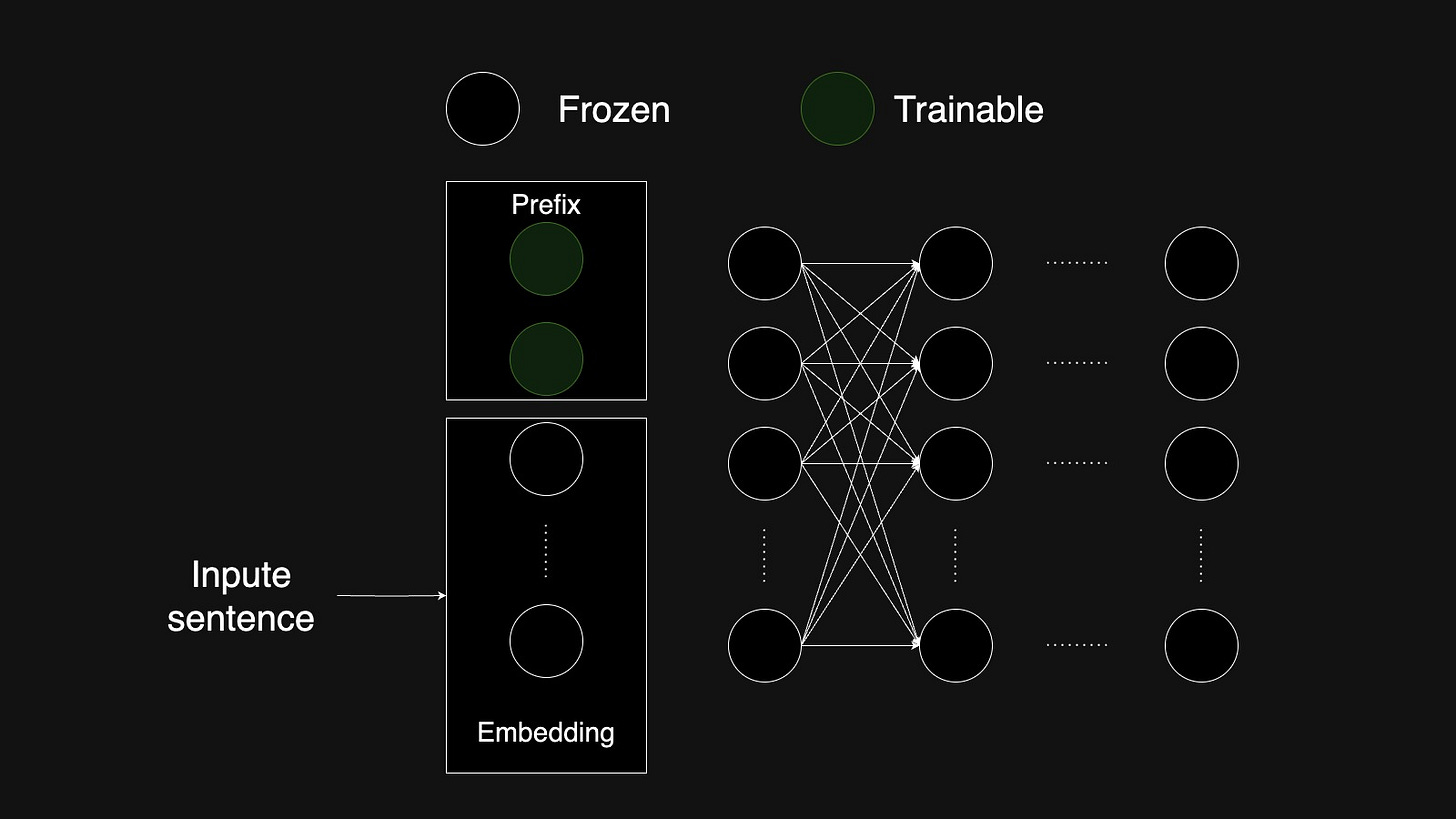
Embedding Prefix

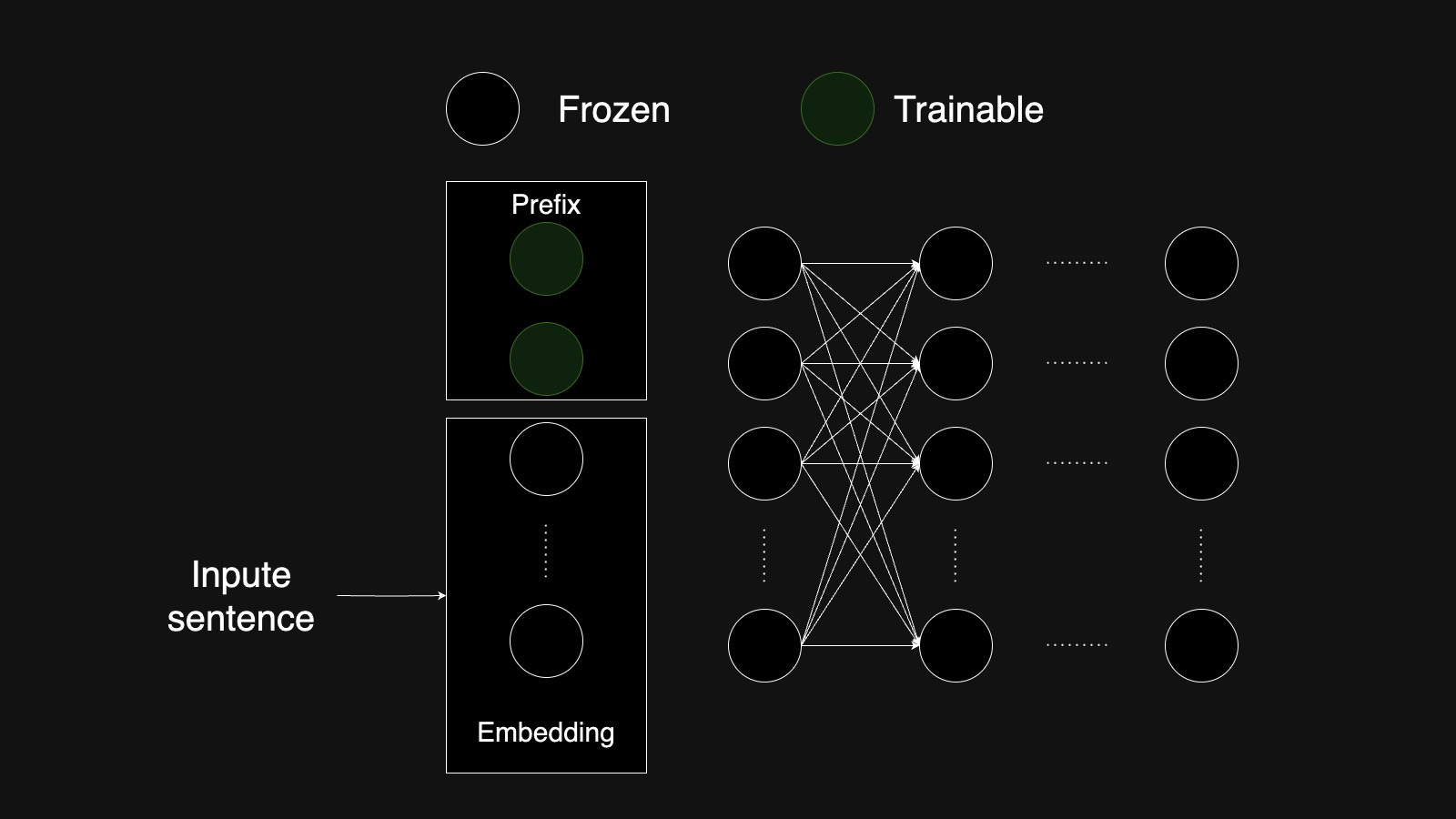
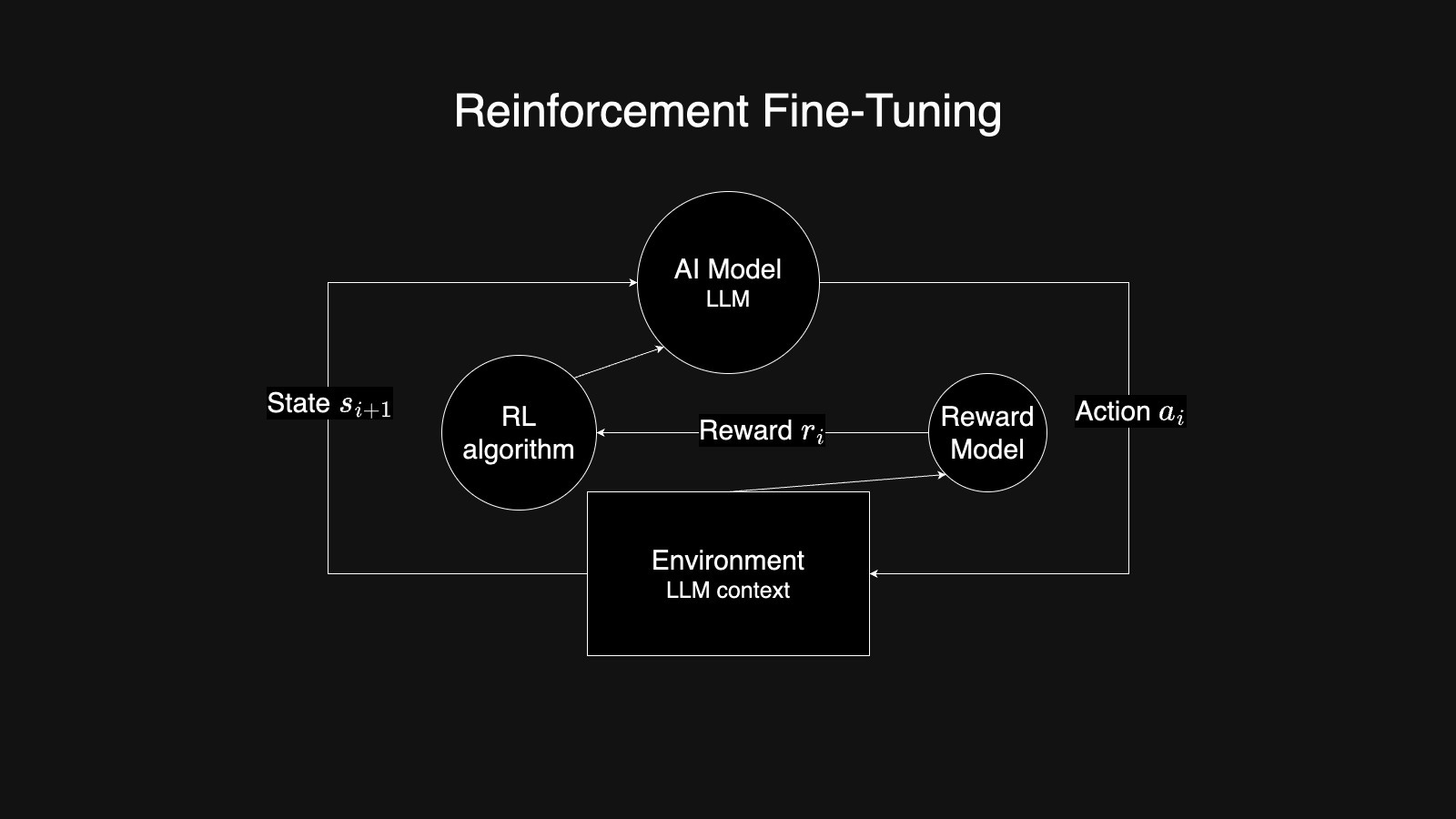
Reinforcement Learning Fine-Tuning
In traditional machine learning, reinforced learning refers to the process that lets the model interact with the environment. The model itself will be improved during the interaction with the environment. The model usually takes an action and provides it to the environment, and the environment will return the model to the next state and the reward to the model. What the model needs to learn in this process is to learn how to take action to maximize the reward it received.
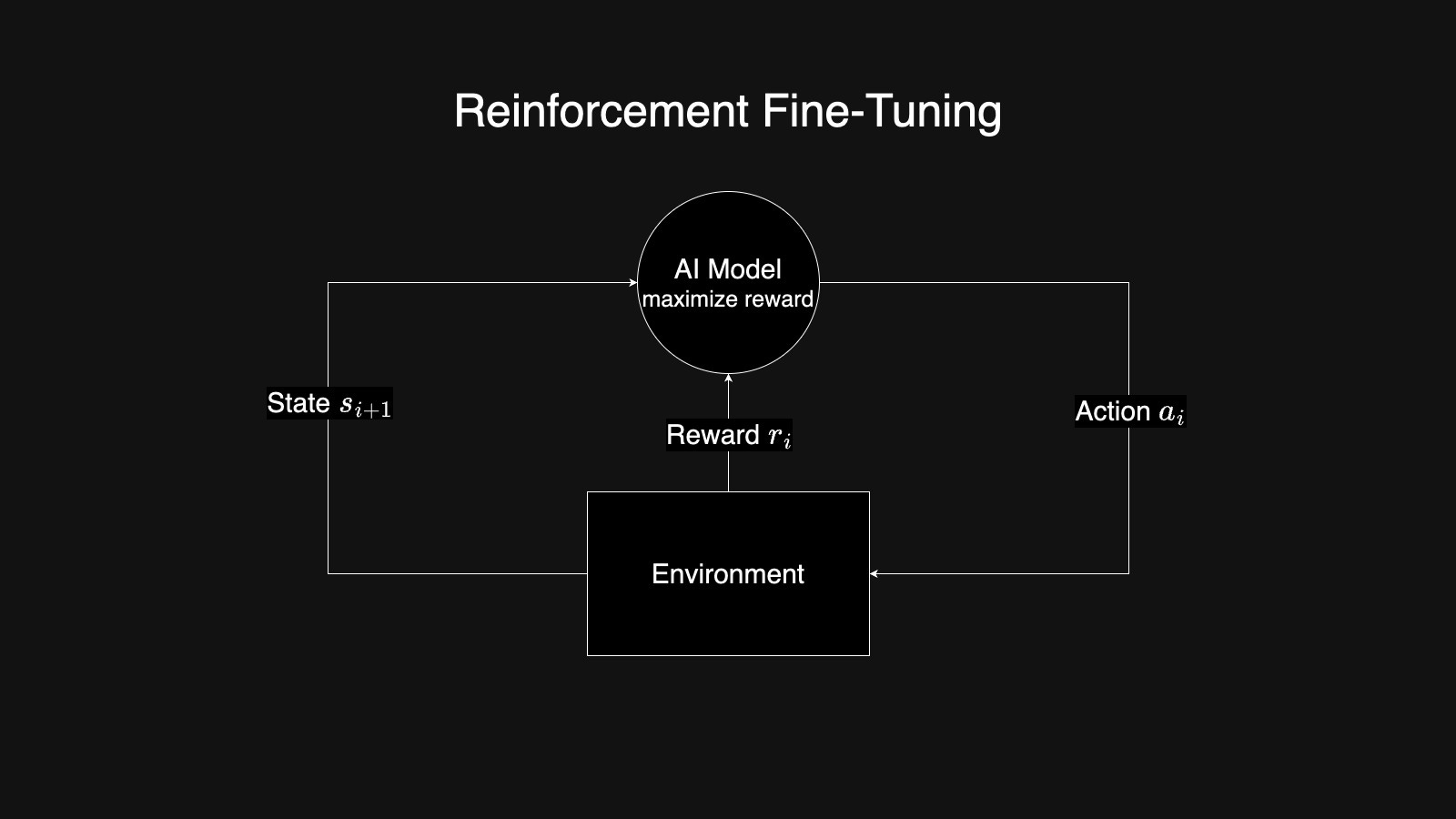
As for the LLM, the LLM here is the model, and the environment will be the LLM context. Or you can see it as prompt + completion for simplicity. We usually train another simple model that calculates the reward based on model output and the actual result. In the OpenAI release video, they call this model as Grader.
With the reword from the reward model, we will apply Reinforcement Learning Algorithms to guide LLM how to change itself. Then that’s the Reinforcement Learning Fine-Tuning process.